DOCENTE: Carlos
Alberto Delgado
NOMBRE: __________________________________________FECHA: _____________ NOTA: _________
El
siguiente texto es una modificación de un escrito original cuyas referencias
están al final y tomado de: https://es.khanacademy.org/science/biology/gene-expression-central-dogma/central-dogma-transcription/a/the-genetic-code-discovery-and-properties
El
Código Genético
El código genético relaciona los grupos de nucleótidos en un ARNm
con los aminoácidos en una proteína. Codones de inicio, codones de terminación,
marco de lectura.
Introducción
¿Alguna vez le has escrito un mensaje secreto a alguno de tus
amigos? Si es así, tal vez hayas usado algún código para mantener el mensaje
oculto. Por ejemplo, tal vez hayas reemplazado letras de las palabras con
números o símbolos siguiendo un conjunto particular de reglas. Para que tu
amigo pueda entender el mensaje, es necesario que conozca el código y aplique
el mismo conjunto de reglas, en reversa, para decodificarlo.
Decodificar mensajes también es un paso clave en la expresión
génica, donde la información de un gen se lee para construir una proteína. En
este artículo revisaremos con más detalle el código genético, el cual
permite que las secuencias de ADN y de ARN se "decodifiquen" en los
aminoácidos de una proteína.
Antecedentes: fabricación de una proteína
Los genes que contienen instrucciones para generar proteínas se
expresan en un proceso de dos pasos.
·
En la transcripción, la secuencia de
ADN de un gen se "reescribe" en forma de ARN. En eucariontes, el ARN
debe someterse a etapas de procesamiento adicionales para convertirse en ARN mensajero, o ARNm. Ver los
siguientes dos videos
·
En la traducción, la secuencia de
nucleótidos del ARNm se "traduce" en una secuencia de aminoácidos de
un polipéptido (cadena proteica).
Codones
Las células decodifican el ARNm al leer sus nucleótidos en
grupos de tres, conocidos como codones.
A continuación, algunas características de los codones:
·
La mayoría de los codones
especifican un aminoácido
·
Tres codones de "terminación"
marcan el fin de una proteína
·
Un codón de "inicio",
AUG, marca el comienzo de una proteína y además codifica para el aminoácido
metionina.
Los codones en un ARNm se leen durante la traducción; se
comienza con un codón de inicio, y se sigue hasta llegar a un codón de
terminación. Los codones de ARNm se leen de 5' a 3' y especifican el orden de
los aminoácidos en una proteína de N-terminal (metionina) hasta C-terminal.
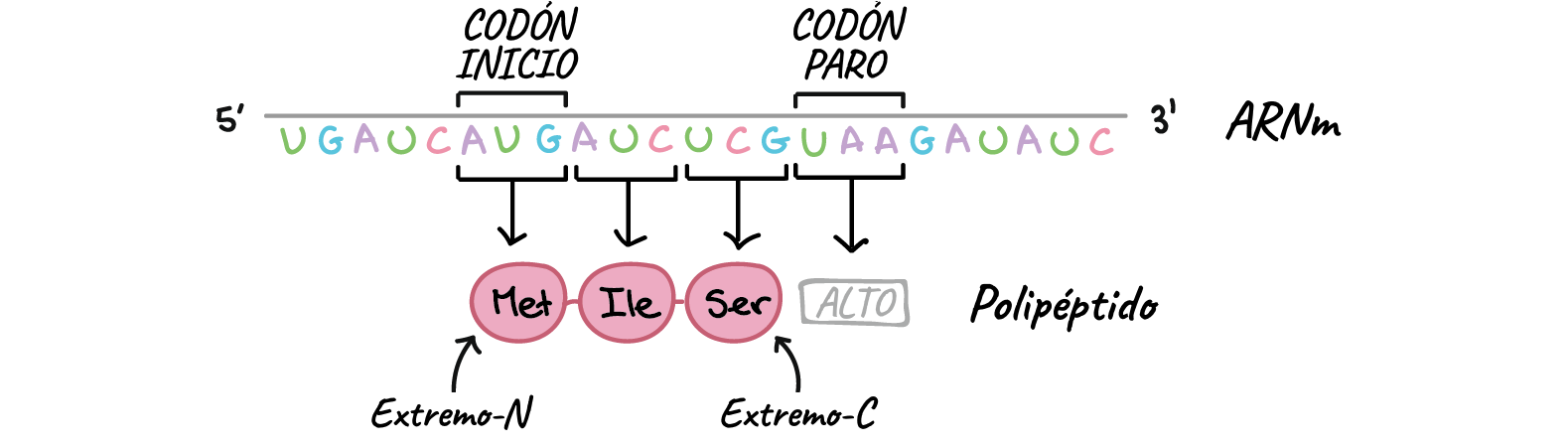
La secuencia del ARNm es:
3'-AUGAUCUCGUAA-5'
La traducción implica leer los
nucleótidos del ARNm en grupos de tres, cada uno de los cuales especifica un
aminoácido (o proporciona una señal de terminación que indica que ha finalizado
la traducción).
3'-AUG
AUC UCG UAA-5'
AUG metionina (inicio)
AUC isoleucina UCG serina UAA "alto"
Secuencia del polipéptido:
(extremo-N) metionina-isoleucina-serina (extremo-C)
Para mayor claridad veamos los
siguientes videos en su orden:
o mejor de
nuevo en español
La tabla
del código genético
El conjunto completo de
relaciones entre los codones y los aminoácidos (o señales de terminación) se
conoce como el código
genético. Con frecuencia, el código genético se resume como una
tabla:
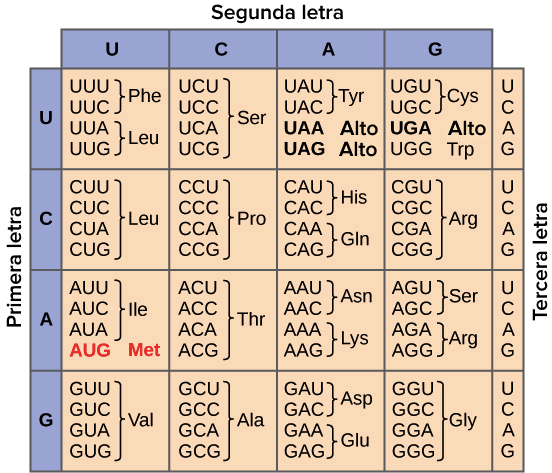
Tabla del código genético.
Cada secuencia de tres letras
de nucleótidos de ARNm corresponde a un aminoácido en específico o a un codón
de terminación. UGA, UAG y UAA son codones de terminación. AUG es el codón de
metionina además de ser el codón de inicio.
Observa como en la tabla muchos aminoácidos están representados
por más de un codón. Como ejemplo, hay seis formas distintas de
"escribir" leucina en el lenguaje del ARNm (trata de ver si puedes
encontrar las seis).
Una característica importante del código genético es que es
universal. Es decir, con pequeñas excepciones, prácticamente todas las especies
(desde las bacterias hasta tú mismo) usan el código genético que se muestra
arriba para la síntesis de proteínas.
Y aquí están los 20
aminoácidos y las siglas para representarlos: Tomada de https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj-fYKm7Zg3McXOKhflCpVNFNuih3-8wnbiCcA91nnVdZjC6NPtApV6JflvlZdZlPo9Wndl4QKzJ_G9a3BYGdY5biL3Da0OrvBthp2g4f8j9Mc6IXUfV3uCpKmTeuk8nUbwvj2QyOsbYR0/s1600/20+AMINOACIDOS.gif

Marco de
lectura
Para llegar de un ARNm a una proteína de manera fiable,
necesitamos un concepto adicional: el de marco de lectura. El marco de lectura determina
cómo se divide la secuencia de ARNm en codones durante la traducción.
Ese es un concepto bastante
abstracto, así que examinemos un ejemplo para entenderlo mejor. El ARNm a
continuación puede codificar tres proteínas totalmente diferentes, según el
marco de lectura con el que se lea.
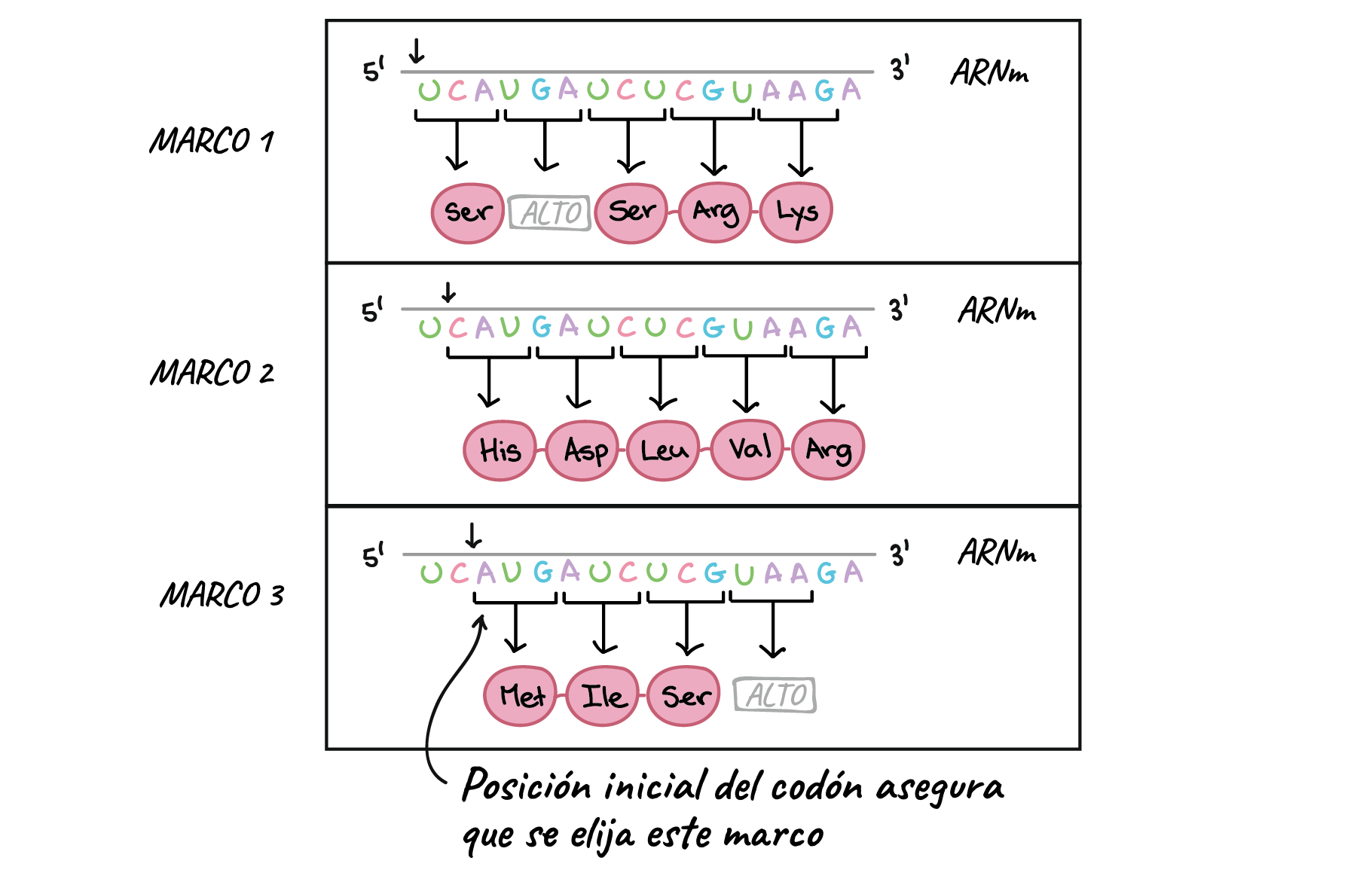
Secuencia de ARNm: 5'-UCAUGAUCUCGUAAGA-3'
Lectura en el marco 1:
5'-UCA UGA UCU CGU AAG A-3'
Ser-ALTO-Ser-Arg-Lys
Lectura en el marco 2:
5'-U CAU GAU CUC GUA AGA-3'
His-Asp-Leu-Val-Arg
Lectura en el marco 3:
5'-UC
AUG AUC UCG UAA GA-3'
Met (inicio)-Ile-Ser-ALTO
La posición del codón de inicio
asegura que se elija el marco 3 para traducir el ARNm.
Así, ¿cómo sabe una célula cuál de estas proteínas hacer? La
clave es el codón de inicio. Puesto que la traducción comienza en el codón de
inicio y sigue en grupos sucesivos de tres, la posición del codón de inicio
asegura que el ARNm se lea en el marco correcto (en el ejemplo anterior, el
marco 3).
Las mutaciones (cambios en el
ADN) que insertan o eliminan uno o dos nucleótidos pueden cambiar el marco de
lectura y causan la producción de una proteína incorrecta "aguas
abajo" del lugar de la mutación:
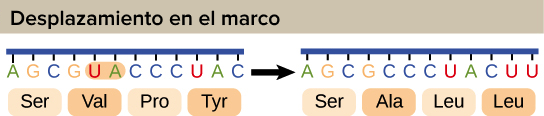
La ilustración muestra una
mutación de marco de referencia donde el marco de lectura se altera por la
deleción de dos aminoácidos.
¿Cómo se descubrió el código
genético?
La historia de cómo se descubrió el código genético es bastante
genial y épica. Hemos guardado nuestra versión en la siguiente sección
emergente con el fin de no distraerte si tienes prisa. Sin embargo, si tienes
un poco de tiempo, sin duda es una lectura interesante.
Descubrimiento del código
Para descifrar el código genético, los investigadores
necesitaban averiguar cómo las secuencias de nucleótidos de una molécula de ADN
o ARN podían codificar la secuencia de aminoácidos de un polipéptido.
¿Por qué era esto un problema difícil? Imaginemos un código muy
simple para darnos una idea. En este código, cada nucleótido en la molécula de
ADN o ARN puede codificar un aminoácido en una proteína. Pero en realidad este
código no puede funcionar ya que comúnmente existen 20 aminoácidos en las proteínas
y solo 4 bases de
nucleótidos en el ADN o ARN.
Entonces, el código tenía que implicar algo más complejo que una
correspondencia de uno a uno entre los nucleótidos y los aminoácidos. ¿Pero
qué?
La hipótesis del triplete
A mediados de la década de 1950, el físico George Gamow amplió
esta línea de pensamiento y predijo que probablemente el código genético estaba
compuesto de tripletes de nucleótidos. En otras palabras, propuso que un grupo
de 3 nucleótidos
en un gen podrían codificar un aminoácido en una proteína.
El razonamiento de Gamow era que incluso un código de dobletes (2 nucleótidos por
aminoácido) tampoco funcionaría, puesto que solo permitiría 16 grupos ordenados de
nucleótidos (4 elevado al cuadrado),
insuficientes para representar los 20 aminoácidos que normalmente se usan para
generar proteínas. No obstante, un código basado en tripletes parecía
prometedor: dicho código permite 64 secuencias únicas de nucleótidos (4 elevado al cubo), más que
suficientes para cubrir los 20 aminoácidos.
Gamow tenía algunas otras ideas no tan correctas sobre cómo se
leería el código (por ejemplo, pensaba que los tripletes se traslapaban, y
ahora sabemos que no es el caso). Sin embargo, su idea principal —que un código
de tripletes era lo "mínimo" que podría cubrir todos los aminoácidos—
resultó ser correcta.
La correspondencia entre codones y aminoácidos
La hipótesis de tripletes de Gamow parecía lógica y se aceptó
ampliamente. Sin embargo, no se había probado experimentalmente y los
investigadores seguían sin saber cuáles eran los tripletes de nucleótidos
correspondientes a cada aminoácido.
En 1961 se comenzó a descifrar el código genético con el trabajo
del bioquímico estadounidense Marshall Nirenberg. Por primera vez, Nirenberg y
sus colegas fueron capaces de identificar los tripletes específicos de
nucleótidos que correspondían a aminoácidos en particular. Su éxito se debió a
dos innovaciones experimentales:
-
Una manera de generar moléculas
de ARNm artificial con secuencias específicas y conocidas.
-
Un sistema para traducir ARNm en
polipéptidos fuera de la célula (un sistema "libre de células").
El sistema de Nirenberg estaba compuesto de citoplasma de
células lisadas de E.
coli, las cuales contienen todos los materiales necesarios para la
traducción.
Primero, Nirenberg sintetizó una molécula de ARNm compuesta
únicamente del nucleótido uracilo (llamada poli-U). Al añadir ARNm de poli-U al
sistema libre de células, encontró que los polipéptidos generados estaban compuestos
exclusivamente del aminoácido fenilalanina. Puesto que en el ARNm de poli-U
solo hay tripletes UUU, Nirenberg concluyó que UUU debía codificar para
fenilalanina. Usando la misma técnica, demostró que el ARNm de poli-C se
traducía en polipéptidos compuestos exclusivamente del aminoácido prolina, lo
que sugería que el triplete CCC podría codificar para prolina.
Secuencia de ARNm:
5'-...UUUUUUUUUUUU...-3' (ARNm de poli-U)
UUU → fenilalanina
(Phe)
Secuencia polipeptídica: (N terminal)...Phe-Phe-Phe-Phe...(C
terminal)
Otros investigadores, como el
bioquímico Har Gobind Khorana en la Universidad de Wisconsin, ampliaron el
experimento de Nirenberg al sintetizar ARNm artificiales con secuencias más
complejas. Por ejemplo, en un experimento Khorana generó un ARNm poli-UC
(UCUCUCUCUC…) y lo agregó a un sistema libre de células similar al de Nirenberg.
El ARNm poli-UC se tradujo en polipéptidos con un patrón que alterna los
aminoácidos serina y leucina. Estos y otros resultados confirmaron que el
código genético se basa en tripletes o codones. Hoy sabemos que la serina está codificada
por el codón UCU, mientras que la leucina está codificada por CUC.
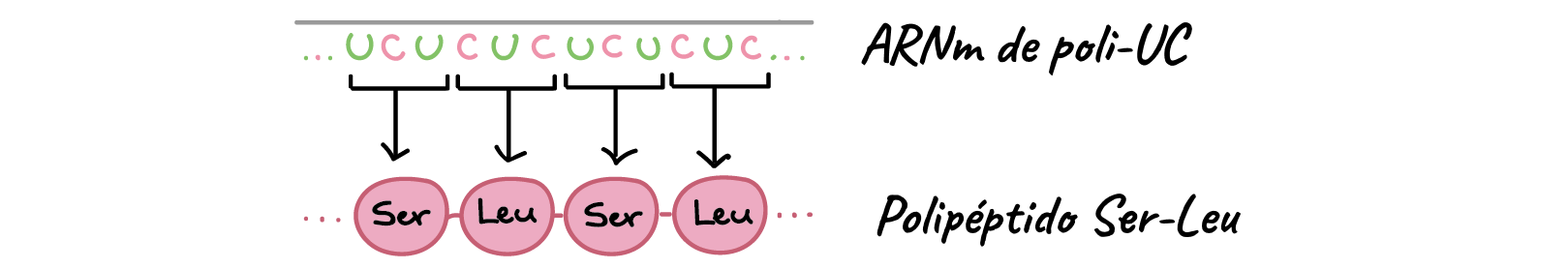
Secuencia de ARNm:
5'-...UCUCUCUCUCUC...-3' (ARNm de poli-UC)
UCU →Serina (Ser)
CUC → leucina
(Leu)
Secuencia polipeptídica: (N
terminal)...Ser-Leu-Ser-Leu...(C terminal)
En 1965, con ayuda del sistema libre de células y otras
técnicas, Nirenberg, Khorana y sus colegas ya habían descifrado completamente
el código genético. Esto es, ya habían identificado el aminoácido o señal de
"alto" correspondiente a cada uno de los 646464 codones de
nucleótidos. Por sus contribuciones, Nirenberg y Khorana (junto con otro
investigador del código genético, Robert Holley) recibieron el premio Nobel en
1968.
Créditos:
Este artículo es un derivado
modificado de "The genetic code(Se abre
en una ventana nueva)(Se abre en una ventana nueva)," por OpenStax College, Biology, CC
BY 4,0(Se abre en una ventana nueva)(Se abre en una ventana
nueva)(Se abre en una ventana nueva). Descarga el artículo original sin costo en http://cnx.org/contents/185cbf87-c72e-48f5-b51e-f14f21b5eabd@10,59(Se abre en una ventana nueva)(Se abre en una ventana nueva)(Se
abre en una ventana nueva).
Referencias citadas:
1. Lorch, M. (16 de agosto de 2012). The most beautiful
wrong ideas in science (Las ideas erróneas más hermosas en la ciencia).
En Chemistry
blog. Consultado en http://www.chemistry-blog.com/2012/08/16/the-most-beautiful-wrong-ideas-in-science/.
2.
Nirenberg,
M. (2004). Historical review: Deciphering the genetic code – a personal account
(Revisión histórica: descifrar el código genético, un relato personal). TRENDS in Biochemical Sciences, 29(1), 46-54. http://dx.doi.org/10,1016/j.tibs.2003,11.009.
3. Gellene, Denise. (14 de noviembre de 2011). H. Gobind
Khorana, 89, Nobel-winning scientist, dies (H. Gobind Khorana, científico
ganador del Premio Nobel, muere a los 89 años de edad). The Nueva York Times.
Consultado en http://www.nytimes.com/2011/11/14/us/h-gobind-khorana-1968-nobel-winner-for-rna-research-dies.html?_r=0.
4. H. Gobind Khorana – Nobel Lecture (Conferencia Nobel).
NobelPrize.org. Nobel Media AB 2019. Lunes 6 de mayo de 2019. https://www.nobelprize.org/prizes/medicine/1968/khorana/lecture/
Referencias:
Arnaud, M.B., Inglis, D.O., Skrzypek, M.S., Binkley,
J., Shah, P., Wymore, F., Binkley, G., Miyasato, S.R., Simison, M. y Sherlock,
G. (2013). CGD help: Non-standard genetic codes (Temas de ayuda en CGD: códigos
genéticos inusuales). En Candida genome database.
Consultado en http://www.candidagenome.org/help/code_tables.shtml.
Gellene, Denise. (14 de noviembre de 2011). H. Gobind
Khorana, 89, Nobel-winning scientist, dies (H. Gobind Khorana, científico
ganador del Premio Nobel, muere a los 89 años de edad). The Nueva York Times.
Consultado en http://www.nytimes.com/2011/11/14/us/h-gobind-khorana-1968-nobel-winner-for-rna-research-dies.html?_r=0.
Guevara Vasquez, F. (2013). Cracking the genetic code
(Descifrando el código genético). En ACCESS - cryptography 2013.
Consultado en http://www.math.utah.edu/~fguevara/ACCESS2013/Cracking_the_Code.pdf.
Nirenberg/Khorana: Breaking
the genetic code. (Nirenberg/Khorana:
descifrando el código genético; s.f.). Consultado en http://www.mhhe.com/biosci/genbio/raven6b/graphics/raven06b/howscientiststhink/14-lab.pdf.
Nirenberg, M. (2004). Historical review: Deciphering
the genetic code – a personal account (Revisión histórica: Descifrando el
código genético, un relato personal). TRENDS in Biochemical Sciences, 29(1), 46-54. http://dx.doi.org/10,1016/j.tibs.2003,11.009 0.
Nirenberg, M. y Leder, P. (1964). RNA codewords and
protein synthesis (El código de ARN y la síntesis de proteínas). Science, 145(3639),
1399-1407. http://dx.doi.org/10,1126/science.145,3639.1399.
Nirenberg, M. W. y Matthaei, J. H. (1961). The
dependence of cell-free protein synthesis in E. coli upon
naturally occurring or synthetic polyribonucleotides (La síntesis de proteínas
libre de células con E. coli depende de polirribonucleótidos naturales o
sintéticos). PNAS, 47(10), 1588-1602. http://dx.doi.org/10,1073/pnas.47,10.1588.
Office of NIH History. (s.f.). The poly-U experiment (El experimento de
poli-U). En Deciphering the genetic code:
Marshall Nirenberg. Consultado en https://history.nih.gov/exhibits/nirenberg/HS4_polyU.htm.
Openstax College, Biology. (29 de septimbre, 2015).
The genetic code (El código genético). En OpenStax CNX.
Consultado en http://cnx.org/contents/GFy_h8cu@9,87:QEibhJMi@8/The-Genetic-Code.
Purves, W. K., Sadava, D. E.,
Orians, G. H. y Heller, H.C. (2004). The genetic code (El código genético).
En Life:
The science of biology (7° ed., págs. 239-241). Sunderland,
MA: Sinauer Associates.
Raven, P. H., Johnson, G. B.,
Mason, K. A., Losos, J. B. y Singer, S. R. (2014). The genetic code (El código genético). En Biology (10°
ed., AP ed., pp. 282-284). Nueva York, NY: McGraw-Hill.
Reece, J. B., Urry, L. A.,
Cain, M. L., Wasserman, S. A., Minorsky, P. V. y Jackson, R. B. (2011). The genetic code (El código genético). En Campbell biology (10°
ed., págs. 337-340). San Francisco, CA: Pearson.
Söll, D., Ohtsuka, E., Jones, D. S., Lohrmann, R.,
Hayatsu, H., Nishimura, S. y Khorana, H. G. (19yl-sRNA's to ribosomes by
ribotrinucleotides and a survey of codon assignments for 20 amino acids
(Estudio sobre polinucleótidos XLIX. Estimulación
de la unión 65). Studies on polynucleotides, XLIX. Stimulation of the binding of aminoacentre aminoacil-ARN y ribosomas por ribotrinucleótidos, y un
estudio sobre la asignación de codones de 20 aminoácidos). PNAS, 54(5), 1378-1385.
Consultado en http://www.ncbi.nlm.nih.gov/pmc/articles/PMC219908/.
ACTIVIDAD PARA ESTUDIANTES DE GRADO 904 Y 905
1. Leer con cuidado realizar
un glosario de términos de mínimo veinte conceptos explicados con sus propias
palabras
2. Crear un polipéptido (mínimo 66 aminoácidos)utilizando el código genético, escribiendo la secuencia de bases nitrogenadas indicando los codones, anticodones y el número de aminoácidos
utilizados. Tener en cuenta los codones de inicio y los de terminación y
utilizar los símbolos o siglas de los aminoácidos para representar el
polipéptido
3. Consultar y escribir
ejemplo de 5 proteínas y su utilidad para el cuerpo humano
Enviar
su trabajo a carlosnatalejo@gmail.com
antes del 26 de marzo......ojo con la corrección mínimo 66 aminoácidos
antes del 26 de marzo......ojo con la corrección mínimo 66 aminoácidos
Profesor una pregunga
ResponderEliminarEl trabajo tiene fecha de entrega
Danna mendieta 904 gracias